


These days, terms like Data Science, Machine Learning, and Artificial Intelligence often swirl together in conversations about technology and data analysis. While they may seem synonymous at first glance, each carries its own distinct significance and applications.
Data Science serves as the foundation, involving the extraction of insights from vast and varied datasets through statistical methods and machine learning algorithms. Machine Learning, situated within the domain of Artificial Intelligence, enables computers to autonomously learn from data and make predictions without requiring explicit programming. Meanwhile, Artificial Intelligence aims to replicate human cognitive processes in machines, spanning diverse domains like natural language processing and robotics.
Harness The Power of Data Science & AI
In this article, we will see what the differences between data science vs. AI/ML are.
Key Takeaways:
Data Science:
- Entails deriving insights from both structured and unstructured data
- Combines statistics, mathematics, and machine learning techniques
- Covers the entire data lifecycle, spanning from collection to visualization
- Addresses challenges like data quality, privacy, and interpretability
Machine Learning:
- Subset of AI focusing on algorithms learning from data
- Improves performance over time with exposure to more data
- Classified into supervised, unsupervised, semi-supervised, and reinforcement learning
- Widely used in various fields for tasks like prediction and classification
Artificial Intelligence:
- Aims to simulate human intelligence in machines
- Encompasses tasks like reasoning, problem-solving, and language understanding
- Includes subfields like machine learning, natural language processing, and robotics
- Raises ethical and societal concerns regarding fairness, privacy, and accountability
Differences:
- Data Science involves extracting insights from data, while ML focuses on algorithms learning from data, and AI simulates human intelligence
- ML is a subset of AI, while data science encompasses techniques from statistics and machine learning
- AI includes broader aspects like robotics and natural language processing, beyond just learning from data
What is Data Science?
Data science is an interdisciplinary domain that employs scientific methods, algorithms, processes, and systems to extract insights and knowledge from both structured and unstructured data. Drawing from diverse disciplines like mathematics, statistics, computer science, and domain expertise, data science integrates various elements to analyze intricate datasets. It reveals patterns, trends, and correlations crucial for informed decision-making and fostering innovation.
Fundamentally, data science encompasses the collection, cleansing, and organization of data, followed by the application of statistical models, machine learning algorithms, and data mining techniques to extract valuable insights. These insights are then used to solve real-world problems, make predictions, optimize processes, and improve business operations across diverse industries such as healthcare, finance, marketing, and manufacturing.
Data scientists are pivotal in harnessing the potential of data to tackle intricate challenges and seize opportunities. They possess a blend of technical skills, including programming languages like Python and R, proficiency in data manipulation and visualization tools, and a deep understanding of statistical concepts and machine learning algorithms.
What Data Science Skills are Required for Data Scientists?
Data Scientists need to master the following skills:
- Programming: R, Python, SQL, SAS, MATLAB, STATA
- Data Wrangling
- Data Visualization
- Data Analysis
- Machine Learning
What are The Current Challenges in Data Science?
As with everything, the field of data science isn’t without its challenges. Challenges in Data Science are:

Data Quality and Quantity
One of the fundamental challenges in data science is ensuring the quality and quantity of data. Data may be incomplete, inconsistent, or inaccurate, leading to biased analysis and flawed insights. Moreover, the sheer volume of data generated daily poses a challenge in terms of storage, processing, and analysis. Addressing these issues requires robust data governance frameworks, data cleaning techniques, and scalable infrastructure.
Data Privacy and Security
With the increasing digitization of society, data privacy and security have emerged as significant concerns. Regulatory frameworks such as GDPR and CCPA impose stringent requirements on the collection, storage, and usage of personal data. Ensuring compliance while leveraging data for insights necessitates a delicate balance between privacy and utility. Additionally, safeguarding data against cyber threats and unauthorized access is paramount to maintaining trust and integrity.
Ethical Considerations
As data science permeates various facets of society, ethical considerations become increasingly pertinent. The potential for algorithmic biases, discriminatory outcomes, and unintended consequences underscores the importance of ethical decision-making throughout the data lifecycle. Transparency, accountability, and fairness should be integral to the development and deployment of data-driven solutions to mitigate ethical risks and promote social responsibility.
Interpretability and Explainability
The growing adoption of complex machine learning models poses challenges in terms of interpretability and explainability. While these models may yield superior performance, understanding how they arrive at decisions is crucial for trust and comprehension. Ensuring models are interpretable enables stakeholders to validate results, identify biases, and make informed decisions based on insights derived from data.
Talent Shortage and Skill Gap
Despite the growing demand for expertise in data science, there persists a shortage of skilled professionals within the field. The multidisciplinary nature of data science requires proficiency in statistics, programming, domain knowledge, and communication skills. Bridging the skill gap necessitates comprehensive education and training programs, collaboration across academia and industry, and fostering diversity to harness the full potential of talent.
What is Artificial Intelligence?
Artificial Intelligence is a discipline within computer science dedicated to developing systems capable of performing tasks traditionally necessitating human intelligence. These tasks include learning, reasoning, problem-solving, perception, understanding natural language, and even interacting with the environment.
In essence, AI seeks to develop machines that can mimic cognitive functions commonly associated with humans.
There are several approaches to implementing AI, each with its own techniques and methodologies. These include:
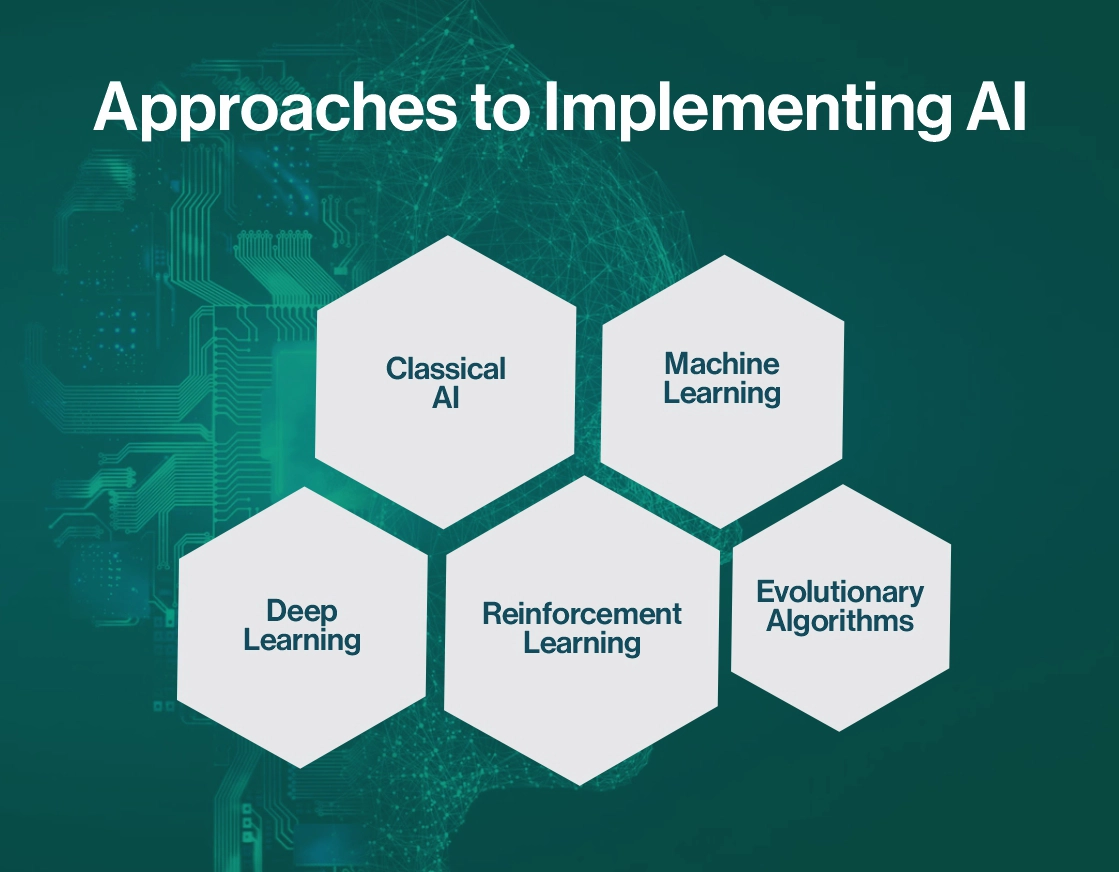
Classical AI
This approach involves representing knowledge and problem-solving strategies using symbols and rules. Systems built on symbolic AI rely on logic and manipulation of symbols to derive conclusions and make decisions. Expert systems, which emulate the decision-making abilities of human experts in specific domains, are an example of symbolic AI.
Machine Learning
Machine learning, a subset of AI, centers on crafting algorithms that can be learned from data. Unlike tasks explicitly programmed, machine learning models are trained on extensive datasets, enabling them to discern patterns and make predictions or decisions autonomously. Techniques such as neural networks, decision trees, and support vector machines are frequently employed in machine learning.
Deep Learning
Deep learning, a distinct subfield of machine learning, entails training artificial neural networks with multiple layers (hence termed “deep”) to execute tasks like image recognition, natural language processing, and speech recognition. In recent years, deep learning has garnered notable success, particularly in domains such as computer vision and language comprehension.
Reinforcement Learning
Reinforcement learning is a paradigm wherein an agent learns to make decisions through interaction with its environment. Through a process of trial and error, the agent receives feedback in the form of rewards or penalties based on its actions, enabling it to develop optimal strategies for achieving its objectives. This approach has found successful applications in diverse domains such as game playing, robotics, and autonomous vehicles.
Evolutionary Algorithms
Inspired by the process of natural selection, evolutionary algorithms involve optimizing solutions to problems by mimicking evolutionary processes such as mutation, recombination, and selection. These algorithms are often used in optimization and search problems where traditional methods may be impractical.
What are The Challenges in Implementing Artificial Intelligence?
Implementing artificial intelligence comes with its own set of challenges, ranging from technical to ethical considerations. Here are some of the key challenges:

Data Quality and Quantity
AI algorithms necessitate substantial quantities of high-quality data to learn efficiently. Nonetheless, acquiring and curating such data can prove to be costly and time intensive. Furthermore, biased or incomplete datasets can result in biased or inaccurate AI models.
Algorithm Selection and Development
Selecting the appropriate algorithm for a particular task can pose a challenge, given that different algorithms exhibit distinct strengths and weaknesses. Crafting custom algorithms or refining existing ones demands expertise and computational resources.
Interpretability and Explainability
Many AI models, especially deep learning models, are often considered “black boxes” because their decision-making processes are not easily understandable by humans. This lack of interpretability raises concerns about accountability, trust, and potential biases in AI systems.
Scalability and Performance
Scaling AI systems to handle large datasets or high volumes of requests while maintaining performance can be difficult. Optimization techniques and efficient hardware infrastructure are essential for achieving scalability without sacrificing performance.
Ethical and Social Implications
AI systems can have unintended consequences and amplify existing biases present in the data they are trained on. Issues such as algorithmic fairness, privacy, and societal impact need to be carefully considered and addressed throughout the development and deployment process.
Regulatory and Legal Compliance
AI systems are obligated to adhere to diverse regulations and legal frameworks, including data protection laws such as GDPR, industry-specific regulations, and ethical guidelines. Ensuring compliance while balancing innovation and societal benefits can be challenging.
Resource Constraints
Developing and deploying AI systems requires significant resources, including skilled personnel, computational power, and financial investment. Access to these resources may be limited, especially for smaller organizations or those operating in regions with less infrastructure support.
Robustness and Security
AI systems are susceptible to adversarial attacks, wherein malicious actors deliberately manipulate input data to deceive the model. Ensuring robustness and security against such attacks is crucial, especially in applications involving sensitive data or critical decision-making.
Human-AI Collaboration
Integrating AI systems into existing workflows and ensuring effective collaboration between humans and AI is essential for maximizing their potential. This involves addressing user acceptance, user interface design, and providing appropriate training for users to interact with AI systems effectively.
Continuous Learning and Adaptation
AI models need to continuously learn and adapt to new data and changing environments to maintain their relevance and performance over time. Developing mechanisms for continuous learning while avoiding concept drift and catastrophic forgetting is an ongoing research challenge.
What is Machine Learning?
Machine learning, a subset of artificial intelligence, concentrates on creating algorithms and statistical models that empower computers to learn from data and make predictions or decisions without explicit programming. In other words, machine learning algorithms allow computers to learn from patterns and experiences in data, and then use that knowledge to make predictions or decisions about new data.
The process of machine learning typically involves the following steps:
Data Collection
Gathering relevant data from various sources. This data could be structured, such as in databases, or unstructured, such as text or images.
Data Preprocessing
Cleaning and preparing the data for analysis. This step may involve tasks such as removing irrelevant information, handling missing values, and converting data into a suitable format.
Feature Selection/Extraction
Identifying the most relevant features or variables from the data that will be used to train the machine learning model. This step helps to improve the model’s performance and efficiency.
Model Training
Utilizing the prepared data to train a machine learning model involves the model learning from the data by adjusting its internal parameters to minimize the disparity between its predictions and the actual outcomes.
Model Evaluation
Assessing the performance of the trained model using validation data or techniques such as cross-validation. This step helps to ensure that the model generalizes well to unseen data and performs accurately in real-world scenarios.
Model Deployment
Deploying the trained model into production systems where it can be used to make predictions or decisions on new data.
Machine Learning Models
Machine Learning (ML) models can be broadly categorized into several types based on their learning approach and the availability of labeled data. Here’s an overview of the main categories:
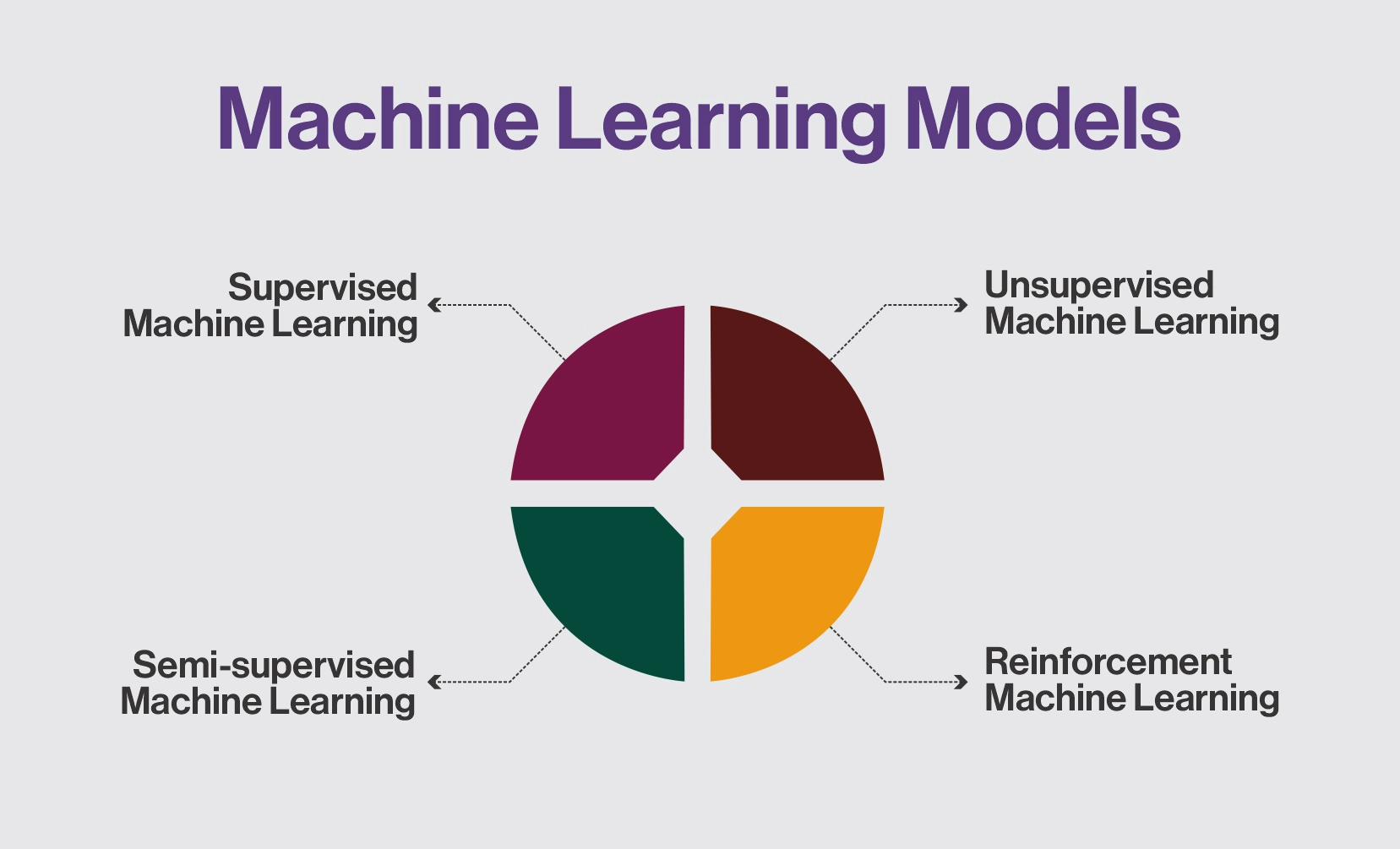
Supervised Machine Learning
Supervised Machine Learning involves training models on labeled datasets, enabling them to learn the mapping between inputs and outputs for prediction or classification tasks. Common algorithms include linear regression, decision trees, and neural networks.
Supervised learning is widely used in various fields such as finance, healthcare, and marketing. In finance, for instance, it’s employed for credit scoring, where historical data on loan applicants’ attributes and whether they defaulted or not is used to build predictive models.
Similarly, in healthcare, supervised learning is utilized for disease diagnosis based on patient symptoms and medical test results. Marketing teams often employ supervised learning to predict customer churn, recommending products, and segmenting customers based on their behavior.
Unsupervised Machine Learning
Unsupervised Machine Learning deals with unlabeled data, aiming to find patterns or structures within it without explicit guidance. Techniques like clustering and dimensionality reduction are employed for tasks such as grouping similar data points or reducing feature space.
Unsupervised learning techniques find applications in diverse fields. In customer segmentation, for example, clustering algorithms are used to group customers with similar characteristics, enabling businesses to tailor marketing strategies accordingly.
In anomaly detection, unsupervised learning algorithms help identify unusual patterns in data that could indicate fraudulent activities in finance or faulty equipment in manufacturing.
Dimensionality reduction techniques like PCA find applications in image and speech processing, where reducing the feature space can lead to more efficient processing and storage.
Semi-supervised Machine Learning
Semi-supervised Machine Learning combines labeled and unlabeled data for training, leveraging the small amount of labeled data to generalize patterns to the larger unlabeled dataset. Techniques include self-training and label propagation, useful when labeled data is scarce or expensive.
Semi-supervised learning is particularly useful in scenarios where acquiring labeled data is expensive or time-consuming. For instance, in sentiment analysis of social media data, only a small portion of the data might be labeled, but the model can still learn from the vast amount of unlabeled data to improve its accuracy.
In image recognition tasks, where labeling images can be labor-intensive, semi-supervised learning enables leveraging both labeled and unlabeled data to enhance model performance.
Reinforcement Machine Learning
Reinforcement Machine Learning involves agents learning to make decisions by interacting with environments, receiving feedback in the form of rewards or penalties. Algorithms like Q-learning and deep Q-networks are employed in tasks like game playing and robotics, optimizing policies to maximize cumulative rewards over time.
Reinforcement learning finds applications in autonomous systems such as self-driving cars and robots. In autonomous vehicles, RL algorithms learn to navigate complex environments by receiving rewards (or penalties) based on their actions, such as staying within lanes and avoiding collisions.
In robotics, reinforcement learning is used for tasks like grasping objects, where the robot learns through trial and error to pick up objects with varying shapes and textures.
Difference Between Data Science Vs. AI/ML
AI, machine learning, and data science are frequently interchanged, yet they denote distinct concepts within the sphere of technology and data analysis. Here’s a breakdown of the differences:
| AI | Machine Learning | Data Science |
|---|---|---|
| AI denotes the emulation of human intelligence processes by machines, commonly computer systems. These processes encompass learning, reasoning, problem-solving, perception, and language comprehension. | Machine learning, a subset of AI, concentrates on crafting algorithms and statistical models enabling computers to execute tasks without explicit programming. | Data science is a multidisciplinary domain focused on deriving insights and knowledge from both structured and unstructured data. It integrates components of statistics, mathematics, computer science, domain expertise, and machine learning. |
| The objective of AI is to develop systems capable of executing tasks typically necessitating human intelligence. These tasks span from basic activities like identifying patterns in data to intricate ones such as comprehending natural language or making decisions. | Machine learning algorithms learn iteratively from data and enhance their performance over time with increased exposure to data. The primary objective of machine learning is to empower computers to learn from experience (data) and autonomously enhance their performance. | Data science encompasses the entire data lifecycle, including data collection, cleaning, analysis, visualization, interpretation, and communication of findings. |
| AI encompasses various subfields, including machine learning, natural language processing (NLP), computer vision, robotics, expert systems, and more. | Machine learning algorithms can be classified into supervised learning, unsupervised learning, semi-supervised learning, reinforcement learning, and other specialized techniques. | Data scientists use a variety of techniques, algorithms, and tools from statistics and machine learning to extract meaningful insights and make data-driven decisions. |
Conclusion
Although commonly used interchangeably, Data Science, Machine Learning, and Artificial Intelligence are distinct yet interconnected domains within the realm of technology and data analysis.
Data Science encompasses the extraction of insights from both structured and unstructured data, utilizing techniques from statistics, mathematics, and machine learning. Meanwhile, Machine Learning, a subset of AI, concentrates on crafting algorithms that facilitate computers to learn and make predictions based on data.
Meanwhile, AI encompasses broader aspects of simulating human intelligence in machines, including tasks like reasoning, problem-solving, and language understanding. Understanding the differences and overlaps between these disciplines is crucial for harnessing their potential to address complex challenges and drive innovation.
FAQs
Which is Better AI, ML, or Data Science?
AI, ML, and Data Science are interconnected but serve different purposes. AI focuses on creating intelligent systems that can simulate human behavior, ML is a subset of AI that enables machines to learn from data without explicit programming, and Data Science involves extracting insights and knowledge from data. Each has its own importance depending on the application, but none is inherently “better” than the others; they complement each other in solving complex problems.
Will AI Replace Data Scientist?
AI will not entirely replace data scientists but will augment their capabilities, leading to a collaborative future where both works together synergistically.


